In the presentation he stresses a few fundamental programming concepts which are in my opinion
quite similar and relevant to the challenges we face today in the field of
BigData.
Remarkably beautiful (and amazingly feeding my personal
enthousiasm) is the fact that the background of this sotry is the so called ‘Demoscene’. The paradigm where art, math, coding and
experience meet.
The first similarirty between old-skool-demo-coding and programming applications in the field of BigData is 'Dealing with limitations': In the art of
demo-programming, the programmer (coder) is faced with limitations of the
machine (regardless whether it is a C64, a GPU card, or a quad-core PC he/she
is coding for). It is the coders’ combination of skills in programming, math,
smartness and art, that makes the difference in dealing with these limitations. The succes comes with the 'wow-experience' of the coder (and the public). Today, similar challenges hold for applications in the field of BigData. There are limitations
to be able to deal with the amount and variety of data. Similar skills and value of algorithms make
the difference of an applications' success.
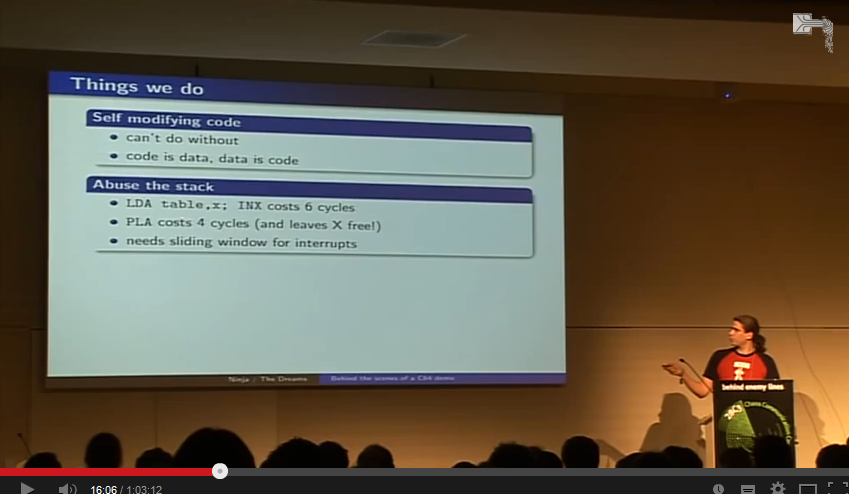
The second similarity showed up when I saw the the killer line in his presentation: 'Data is code and Code is Data'. This holds
for self-modifying code on the C64, as he explains, but -of-course- also for BigData
analytics applications. Let me try to explain this in a few lines: Consider the common see-do/plan-act cycle, where data is taken from a particular
environment, then information is
extracted from that data, followed by feeding this information into decision support systems and finally, taking actions based on those decisions, back into the same environment as where the data was
taken. These steps come with algorithms that use parameters
being derived from that same environment, either obtained automatically (thanks to a learning algorithms) or empirically retrieved by humans observing the same environment. The data is changed by the code, and the code is tuned by the data. The concept holds for that old C64 but also for our todays' paradigm of BigData.
Sometimes I think that there
are only a few types on the dancefloor in this universe: humans, machines, algorithms and
data...
Geen opmerkingen:
Een reactie posten